| Ito Math and Brownian Motion ... an appendix to Part II |
Patient Reader: Here comes the hard part. This and the next section or two are replete with math, yet it is less than rigorous, the arguments are somewhat fuzzy and certain details are omitted - mainly because I don't fully understand them! For the mathematically challenged (like me?), this won't be a problem. After reading several explanations (I'll stick a list of references at the end), I find it all quite fascinating, but difficult and confusing. However, if you forge ahead and get some notion of what Ito is all about, then I will have accomplished my mission. My understanding is somewhat akin to my knowledge of the internal combustion engine. I rarely look under the hood except to change the oil ... and a valve job is beyond my ken. But I'm content to know roughly how it works. (I won't be doing a valve job any time soon.)

By the way, the stuff which follows uses calculus (ordinary and partial derivatives,
Riemann integrals, ordinary and partial differential equations, Taylor series - stuff like that) ... so beware!
(T'ain't easy*, but then Black and Scholes won a Nobel prize so what'd y'all expect, eh?)
You may just want to peek at the Summary which
traces the steps from Ito to Black-Scholes.
* Somebuddy said, via e-mail, that it made blood spurt from his ears 
We're going to peek at the Alice-in-Wonderland World of Ito Math, where the common rules of calculus are modified to
include functions that aren't smoooth, but vary wildly, up, down, randomly, each
move independent of the previous move, unpredictable ...
>Hey! That's my stock portfolio because ...
Pay attention.
|
First we have to consider the ordinary, garden-variety Riemann Sum ...
>Huh? Patience. A Riemann Sum goes like so:
Each term, like f(tk)Δt, represents a rectangular area (as shown in dark green, in Figure 1). If we let N increase, meaning that Δt is made smaller and smaller,
then (as seen in Figure 2), the sum of all the rectangular areas (that's our Riemann Sum) approaches ...
This limit is a so-called Riemann Integral. That'll be thing #1
|  Figure 1
|

|
So far, so good. We need one other thing:
[f(tk+1) - f(tk)] / Δt is the slope of the chord,
from the point where t = tk However, if f(t) is a smooth (i.e. differentiable) function, then it's also the slope of the tangent at some point
between tk and tk+1. Such a point is labelled sk in Figure 3. That means ...
| 
Figure 3 |
Okay. Let's forge ahead.
We'll consider the following sum, called the Quadratic Variation of the function f on the interval [0,T].
As before, we select points in the interval [0,T] and sample f(t) at these points and calculate:
[f(t1) - f(t0)]2 + [f(t2) - f(t1)]1 + [f(t3) - f(t2)]2 + ... + [f(tN) - f(tN-1)]2 = Σ [f(tk+1) - f(tk)]2
Write
[f(tk+1) - f(tk)]2 =
[f '(sk)Δt] 2
and we get:
Σ [f(tk+1) - f(tk)]2 =
Σ[f '(sk)Δt] 2
= Δt Σ f '(sk)2Δt
As Δt ![]() 0 we get:
Σ f '(sk)2Δt
0 we get:
Σ f '(sk)2Δt
![]()
 f '(t)2 dt
and (of course!) Δt
f '(t)2 dt
and (of course!) Δt ![]() 0
0
hence you can guess what their product approaches ...
| If f(t) is a smooth (differentiable) function on [0,T], then
Σ [f(tk+1) - f(tk)]2 |
>So? Is that good? Is that thing #3?
No, it's not #3. It just reminds us of what happens with good-looking functions (not our stochastic functions, as we'll see). For smooth functions it's to be expected, since that little guy, Δt , appears squared. One of them is incorporated into the Integral and the other ...
|
>Makes the result zero? Yes. For smooth functions, the Quadratic Variation is zero. >Wow! Uh ... is that good?
>Huh? Is that #3?
| 
Figure 4 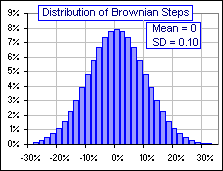
Example with Δt = 0.10 |
[3] A Brownian Motion f(t) has the following properties:
|
For a Brownian Motion, although the average or
Expected value of Δfk = f(tk+1) - f(tk) is 0,
the Expected value of
{Δfk}2
= {f(tk+1) - f(tk)}2 is Δtk.
What that means is:
- We're at f(tk) and we consider just the next time step of size Δtk = tk+1 - tk.
- The (change in f)2, namely [Δfk]2, is
random, so we consider all possible values and calculate its expected value.
It's Δtk = tk+1 - tk, the length of the time-step. - Now we sum all such [Δfk]2, that's Σ Δ2fk where we write Δ2fk as shorthand for [Δfk]2
- That's the sum of all the Δtk, which, of course, is just T.
If we consider just a single Brownian Motion, which we sample at a finite number of points tk,
then its Quadratic Variation can be just about anything. It's a random motion, eh?
However, if we take an infinite number
of points (by letting N![]() infinity), we're talking some kind of average ... of all
possible values of {Δfk}2. We're talking the
Expected value of
{Δfk}2 ... and that'll depend upon the distribution of these steps,
Δfk.
infinity), we're talking some kind of average ... of all
possible values of {Δfk}2. We're talking the
Expected value of
{Δfk}2 ... and that'll depend upon the distribution of these steps,
Δfk.
Okay. Now we take Brownian steps at times t0 = 0, t1, t2, t3, ... tN-1.
>Brownian steps?
What I mean is, we consider some Brownian Motion for t in [0,T] and look at the positions at N time points and ...
>Okay. I understand. Please continue.
Our position ...
>Wait! Are there N time points, t0, t1, ... tN-1?
Well, there are N Brownian steps but, in reality, we have N+1 pertinent time points, including tN = T.
It takes N+1 points to make N time intervals, eh?
Let's forge ahead.
Our position, at each time, is f(0), f(t1), f(t2), f(t3), ... f(tN-1)
the graph of f(t) is like Figure 4
Consider the step sizes, for our Brownian Motion, namely Δfk = f(tk+1) - f(tk)
with k = 0 to k = N-1
>I assume that Δtk = tk+1 - tk is constant.
Uh ... not necessarily. In fact, earlier, we assumed it was constant just to make things easier. It didn't have to be.
When we required Δtk ![]() 0, we just needed to make the
largest of the intervals tk+1 - tk go to zero. That'd make all go to zero, eh?
0, we just needed to make the
largest of the intervals tk+1 - tk go to zero. That'd make all go to zero, eh?
>Mumbo jumbo.
Pay attention.
For convenience we write f(tk) = fk ... and now we do this to calculate the Quadratic Variation:
- Σ Δ2fk = Σ [fk+1 - fk]2 = Σ [f2k+1 - 2fk+1fk + f2k] where the sums are from k = 0 to k = N-1
- In the first sum, f21+ f22 + ... + f2N = f2N - f20 + Σ f2k where the sum is again from k = 0 to k = N-1
- Hence Σ Δ2fk = f2N - f20 + Σ [f2k - 2fk+1fk + f2k] = f2N - f20 + 2Σ [f2k - fk+1fk] = f2N - f20 - 2Σ fk(fk+1 - fk)
- Rearranging, we get: Σ fk(fk+1 - fk) = (1/2) (f2N - f20) - (1/2)Σ Δ2fk
- Or, equivalently, Σ f(tk)Δfk = (1/2) [f2(tN) - f2(t0)] - (1/2)Σ Δ2fk
f(t) df(t) and, for our Brownian Motion, the Quadratic Variation Σ Δ2fk
So we get thing #4:
|
[4]
If f(t) is a Brownian Motion on [0,T], then f(t) df(t) = (1/2) [f2(T) - f2(0)] - T/2
|
>If f(t) were smooth, then ... uh ...
Then the T/2 term would be missing.
>Are we there yet?
Heavens, no. This stochastic / Ito stuff is interesting, no?
>No.
Above, we considered the sum of the squares of the changes f(tk+1) - f(tk). Now we consider the square of the sum:
Consider {Σ[f(tk+1) - f(tk)]}2 = {Σ Δf(tk)}2 = {Δf(t0)+Δf(t1)+...+Δf(tN-1)}2.
There'll be all those squared terms, like Δ2f(t3),
and all the cross-product terms, like Δf(t1)Δf(t3) which appear twice,
so we get:
{Σ[f(tk+1) - f(tk)]}2 = Σ Δ2fk + 2Σ ΔfkΔfj
However, Σ[f(tk+1) - f(tk)] = [f(t1) - f(t0)] + [f(t2) - f(t1)] + ... + [f(tN) - f(tN-1)] = f(tN) - f(t0).
So:
{f(tN) - f(t0)}2 = Σ Δ2fk + 2Σ ΔfkΔfj
Now let N ![]() infinity and note that (for Brownian Motion), since the steps
Δfk are random and independent, sometimes positive, sometimes negative, then ...
infinity and note that (for Brownian Motion), since the steps
Δfk are random and independent, sometimes positive, sometimes negative, then ...
>Then you're going to put Σ ΔfkΔfj = 0.
In the limit, yes, averaging over all possible sequences of steps and ...
>That's an assumption, right?
It's actually a property of Brownian Motion ... part of the definition. It means the Δfk are independent.
>And one never argues with a definition, right?
Right.
Anyway, from
{f(tN) - f(t0)}2 = Σ Δ2fk + 2Σ ΔfkΔfj
we get, in the limit as N ![]() infinity:
infinity:
{f(T) - f(0)}2 = T
since, for the Quadratic Variation,
Σ Δ2fk
![]() T.
T.
Notice that f(T) - f(0) is how far we've travelled, in our Brownian walk.
>What! Everything is so random, yet you know where it ends up?
We're talking average, where all Brownian motions are considered. At the end of our time period we expect
to have travelled a distance equal to the square root of T. It's a familiar result, no?
>No.
Remember the infamous square-root-of-time thing? (See
SQRT(time).)
Remember, any particular Brownian Motion could end up anywhere. We're talking about the final position averaged over a jillion such motions. Like tossing a coin. You could get a jillion heads, but, on average ...
>Okay. I understand, but a picture would be good about now.
Notice that we may write
Σ Δ2fk
![]() df df = T = dt so, on a differential level,
we have df df = dt.
df df = T = dt so, on a differential level,
we have df df = dt.
>A picture would be good about now.
Didn't you get that? I said df df = dt. Isn't that remarkable?
>So why don't you make it #4?
I see you've lost count. Stay awake:
| [5] If f(t) is a Brownian Motion on [0,T], then df2 = dt |
Consider this:
- Suppose P(x) is a well-behaved function of x, so, using Taylor's Theorem we get:
- P(x+Δx) = P(x) + P'(x)Δx +
(1/2)P''(s)Δ2x
where Δ2x is my shorthand for (Δx)2 and "s" is some point between x and x+Δx, like in Figure 3 - Now suppose that, although P is smooth and sufficiently well-behaved, x is NOT.
- In fact, suppose that x is a function of t, a stochastic function, a Brownian Motion: x = x(t).
- We put Δx = x(tk+1) - x(tk)
Exactly. Proceeding, we ...
>So why don't you just call it f(t), instead of x(t)?
To see if you're still awake.
Proceeding, we write:
P(x+Δx) - P(x) = ΔP = P'(x)Δx + (1/2)P''(s)Δ2x
>Wait! Let me do it!
ΔP/Δt
= P'(x)Δx/Δt +
(1/2)P''(s)Δx2/Δt
= P'(x)Δx/Δt +
(1/2)P''(s)(Δx)(Δx/Δt)
Let Δt ![]() 0 and get dP/dt = P'(x) dx/dt +
(1/2)P''(s)(0)(dx/dt) = P'(x) dx/dt.
0 and get dP/dt = P'(x) dx/dt +
(1/2)P''(s)(0)(dx/dt) = P'(x) dx/dt.
Very good. Equivalently we can write: d/dt P(x(t)) = (dP/dx) (dx/dt), the Chain Rule
(for those who remember their first year calculus).
Alas, the Chain Rule is out the window for our stochastic / Ito calculus, because, although we'd expect
Δ2x/ Δt
= Δx Δx/Δt
![]() (0)(dx/dt) = 0, in fact, for our Brownian x(t), we have:
Δ2x
(0)(dx/dt) = 0, in fact, for our Brownian x(t), we have:
Δ2x ![]() dt
dt
>So Δ2x/Δt ![]() 1?
1?
Yes. In fact, what we really mean by Δ2x ![]() dt
is that Δ2x/Δt
dt
is that Δ2x/Δt ![]() 1.
In fact ...
1.
In fact ...
>I'd say that Δx ![]() 0 as Δt
0 as Δt ![]() 0 so Δ2x
0 so Δ2x ![]() 0
0
Well yes, since x(t) is a continuous function of t.
As you said, we should really write Δ2x/Δt ![]() 1
which makes sense even though Δx and Δt both approach zero.
1
which makes sense even though Δx and Δt both approach zero.
>Huh?
If (for example) u(t) = sin(t) and v(t) = t2 then, although each ![]() 0 as
t
0 as
t ![]() 0, nevertheless u2(t)/v(t)
0, nevertheless u2(t)/v(t) ![]() 1.
1.
Anyway, in our shorthand, differential notation, we're saying that dx2 = dt
(which is the remarkable
df df = dt that I tried to point out earlier).
Our Ito Chain Rule then becomes:
|
[6]
If P(x) is a sufficiently well-behaved function of x and x(t) is a Brownian Motion,
then dP = P'(x) dx + (1/2) P''(x) dt or, in Integral Form
P(x(T)) - P(x(0))
= |
This is Ito's formula. Neat, eh?
Note that, in the first integral, there's a dx (and x(t) is one of those stochastic functions). It's an Ito integral.
On the other hand, the second integral (the one with dt) is an ordinary garden variety Riemann integral.
>Mamma mia! You really understand all this stuff?
I'm just learning ... but it sure is fascinating, eh?
>No.
>I don't know about you, but I think that Brownian Motion stuff is weird.
Okay, let's do this ... a simplified random walk.
- Our steps are taken at times t = 0, 1, 2, 3, ... N-1
- At each time, we step from x(n) to x(n+1)
- Assume the step size is either +1 or -1 with equal probability so the average (or Expected) step size is zero
- Then x(n+1) = x(n) + r(n) where r(n) is either +1 or -1, each with probability 1/2, and E[r(n)] = 0
- Then the average of x(n+1) - x(n) is E[x(n+1) - x(n)] = E[r(n)] = 0
- Further, the average of {x(n+1) - x(n)}2 is E[{x(n+1) - x(n)}2] = E[r2(n)]
- But r2(n) is either (-1)2 = 1 or (+1)2 = 1, hence E[r2(n)] = E[1] = 1
- The random steps r(n) then have Mean = 0 and Variance = E[r2(n)] - {E[r(n)]}2 = 1 - 0 = 1
Variance = (Standard Deviation)2 = (Average of the Squares) - (the Square of the Average). See SD Stuff
>On average?
Yes. We consider a jillion such random walks and calculate the average distance we've travelled. It's like tossing a coin N times to determine the steps for a single random walk with, say, heads meaning move (+1) and tails meaning move (-1), then repeating this N-toss scenario a jillion times.
We have
- x(N) - x(0) = r(0) + r(1) + r(2) + ... + r(N-1) so
- {x(N) - x(0)}2 = {r(0) + r(1) + r(2) + ... + r(N-1)}2 = Σr2(n) + 2Σ r(i)r(j)
- Averaging over a jillion such random walks we get the Expected value as:
E[{x(N) - x(0)}2] = E[Σr2(n)] + 2E[Σ r(i)r(j)] - We're assuming that the r(n) are independent, so E[Σ r(i)r(j)] = 0
- Further, since r2(n) = 1, then Σr2(n) = Σ1 = N so, finally
- E[{x(N) - x(0)}2] = N
>Yeah, but Brownian Motion doesn't have r(n) = +1 or - 1, does it?
No, but remember [3], the Brownian Motion definition? It says
4. The expected value of [f(tk+1) - f(tk)]2 is Δt = tk+1 - tk, that is E[{Δf(tk)}2] = tk+1 - tk
which, in our case, is:
E[{x(tn+1) - x(tn)}2] = E[r2(n)] = tk+1 - tk
In our case, this just happens to be "1", so N time steps of length "1" makes N = total elapsed time ... like N = T.
But the time steps could be different ... in which case consider this:
We have the Expected value of a single term:
E[r2(k)] = tk+1 - tk
Now we determine the Expected value of the SUM: r2(0)+r2(1)+...+r2(N-1)
If r(i) and r(j) independent then*
E[r2(0)+r2(1)+...+r2(N-1)] =
E[r2(0)]+ E[r2(1)]+...+ E[r2(N-1)]
= (t1 - t0)+(t2 - t1)+...(tN - tN-1)
= tN - t0
which is the length of the time interval. (This corresponds to "N" when, earlier, our step size was "1".)
* The Variance of the sum of independent random variables is the sum of the Variances.
>Haven't you already said that?
Repetition, so we understand it, using different words, different symbols, first f then x, first k then n, different ...
>Yeah, I know. To keep me awake. Don't you have any pictures?
Earlier we talked about a stochastic (Brownian) function x(t) on [0,T]
... and its Quadratic Variation and the Variance of the step sizes: Δx(tk).
- Quadratic Variation of x(t) = E[ Σ{x(tk+1) - x(tk)}2] = ΣE[Δ2x(tk)] = T
- Variance of Δx(tk)
= limitN
 infinity{(1/N) [ Σ{Δx(tk)}2 - [ΣΔx(tk)]2]}
= E[Δ2x(tk)]
- E2[Δx(tk)]
infinity{(1/N) [ Σ{Δx(tk)}2 - [ΣΔx(tk)]2]}
= E[Δ2x(tk)]
- E2[Δx(tk)]
Remember? Variance = (Standard Deviation)2 = (Average of the Squares) - (the Square of the Average)
and, as usual, we're writing Δ2x(tk) to mean the square of Δx(tk)
We have to distinguish between:
[A] following a Brownian Motion from t = 0 to t = T (in N time steps with lengths Δtk)
[B] starting at x(tk) and considering the distribution of a jillion possible next steps: Δx(tk)
If, in [A], the number of steps, N, is large (a jillion?), then considering N time steps means we're considering a jillion steps ... so it's similar to situation [B]. In either case it's the distribution of steps that we must be interested in.
For the random motions we're considering, the Mean step size is zero, so E[Δx(tk)] = 0.
That means:
- Variance of Δx(tk) = E[Δ2x(tk)] = Var[Δx(tk)] = Δtk
- Quadratic Variation of x(t) = ΣE[Δ2x(tk)] = ΣVar[Δx(tk)] = ΣΔtk = T
Let's now talk about stock prices, modelled by Ito's stochastic equation:
>It's about time!
Pay attention.
| [Ito-2] dP = μ(t,P)dt + σ(t,P)dB |
- P(t) is the price at time t, and dP its change over a small time interval dt, from t to t+dt.
- B(t) is a Brownian Motion with dB having Mean = 0 and Variance = dt.
- We consider all possible changes, dP, at time t, over the next time increment, dt.
The variability of these changes is governed by the random component σ(t,P)dB. - The average or Expected value of σ(t,P)dB is zero: E[σ(t,P)dB ] = 0.
- The average or Expected value of dP is then given by E[μ(t,P)dt ].
- B(t) is a Brownian Motion so E[dB] = 0, E[dB2] = dt.
- The Variance of dP is the Variance of σ(t,P)dB is the expected value of
{σ(t,P)dB}2
E[{σdB }2] = E[σ2 dt]
Uh ... yes. That's to see ...
>If I'm awake?
Yes.
Anyway, we conclude that:
- The instantaneous Expected value of dP is E[μ(t,P)dt].
- The instantaneous Variance of dP is E[σ2 dt].
- Because of the assumed independence of successive price changes, dP, stock prices have no memory.
- Knowledge of past prices
willshould have no effect on predictions of future prices.
>Instantaneous?
Yes, over the small time interval dt.
>And no effect on future prices?
Yes. That's Market Efficiency.
For our purposes, we'll assume an average rate of change of Price of r so we'll write the first term as
r P dt.
Without any stochastic component, we'd have dP/dt = r P with solution P(t) = P(0)ert.
Further, we'll assume that the stochastic component is s P(t) dB
where "s" measures the Standard Deviation of the random component (hence, of our stock prices).
For the evolution of our stock Prices, we then have:
| [Ito] dP = r P(t) dt + s P(t) dB |
>A picture is worth a thousand ...
Okay, here's what we'll do:
- Let dt = 0.1; that's 1/10 of a day or a month or a year or .... whatever.
- Let r = 0.05; that's a 5% average return per unit time.
The average return over a time of 0.10 would then be 0.1*5% or 0.5% - Let s = 0.01 or 0.05 or whatever; that's the Standard Deviation of the returns over time periods of length dt.
- Let dB be normally distributed with Mean = 0, Standard Deviation = 1.
- Consider a bunch of Price evolutions, starting with P(0) = $10.


Figure 5
Note that, for small volatility (that is, small s-values) the average returns are close to the expected 0.5%, but,
for larger s-values, there's
greater variability.
>You used Excel, right?
Right. I modelled the stock Price evolution via:
Excel-1: P(n+1) = P(n)*(1+r*dt + s*NORMINV(RAND(),0,1))
>See that blue curve, in the right chart?
Yes.
>That's my stock.
Funny. Now consider, for example, a stock modelled via dP = 0.01 P dt + 0.05 P dB so that ...
>Let me do it!
dP/P = 0.01 dt + 0.05 dB so the expected value of dP/P ... that's the return over a time period dt ... that's ... uh ...
That's E[dP/P]
= E[0.01dt + 0.05dB] = E[0.01dt ] + E[0.05dB] = 0.01 dt
The Variance of dP/P is E[(0.05dB)2] = (0.05)2 so the Standard Deviation is 0.05 or 5%.
>That's exact, right? I mean, you get the exact evolution of P(t) by using your
P(n+1) = P(n)*(1+r*dt + s*NORMINV(RAND(),0,1)), right?
Wrong. To get the exact solution to the Ito's stochastic differential equation would require solving [Ito].
What we've done (with our Excel command) is approximate the solution to a stochastic differential equation.
>But Ito's equation can't be solved ... not exactly, right?
Wrong again. The simplified version of dP = μ(t,P)dt + σ(t,P)dB, namely
dP = r P(t) dt + s P(t) dB, with r and s constants, can be solved.
|
[Ito*]
If r and s are constants, then dP(t) = r P(t) dt + s P(t) dB(t) has solution:
P(t) = P(0) exp[(r-s2/2)t + s B(t)] where B(t) is a Brownian Motion |
>How do you prove it's a solution? Just differentiate?
Yes, but VERY carefully.
First off, we need an extended differentiation rule for a function of two variables, one of which is stochastic:
|
[7]
For F(t,x) where x is a Brownian Motion:
dF = Ft dt + Fx dx + (1/2)Fxx dx2 and dx2 = dt |
>I assume Fx means ΔF/Δx?
Yes, the partial derivative. Anyway, we have (with x(t) a Brownian Motion) ...
>Wait! Where did all that come from?
That? You mean [7]?
Taylor series, again:
ΔF = F(t+Δt,x+Δx) - F(t,x) = FtΔt+ FxΔx + (1/2)[FxxΔx2 + 2 FxtΔxΔt + Ftt Δt2] + ...
and, letting Δx and Δt ![]() 0
and putting (in the limit) ΔF = dF, Δx = dx, Δt = dt
and Δx2 = dt.
0
and putting (in the limit) ΔF = dF, Δx = dx, Δt = dt
and Δx2 = dt.
Just remember that, in our new Stochastic World:
Δx2 ![]() dt, ΔxΔt
dt, ΔxΔt ![]() 0, Δt2
0, Δt2 ![]() 0.
0.
Anyway, we have (with x(t) a Brownian Motion):
- F(t,x) = P(0) exp[(r-s2/2)t + s x]
- Ft = (r-s2/2) F
- Fx = s F
- Fxx = s Fx = s2 F
- Hence, using [7], dF = Ft dt + Fx dx + (1/2)Fxx dt = r F dt + s F dx
>That (r - s2/2) ... it looks like it's some average return, eh?
That corresponds to an Annualized Return.
If we set B(t) = 0, we'd have P(t) = P(0) e(r-s2/2)t after t years,
so {P(t)/P(0)}1/t = exp(r-s2/2) is the gain factor per year,
which corresponds to continuous compounding of (r-s2/2) over one year.
>Huh?
A return of R over one year means a return of R/365 per day for 365 days hence (1+R/365)365 for a year
and, continuous compounding means (1+R/N)N ![]() eR as N
eR as N ![]() infinity.
infinity.
>So exp(r-s2/2) means continous compounding of (r-s2/2) per year.
You got it.
In
AM vs GM we obtained an approximation
for the Annualized Return, given the Mean Return and Standard Deviation, namely:
[a] (1+Annualized)2 = (1+Mean)2 - StandardDeviation2, or
or
(1+Annualized)2 = (1+r)2 - s2
which can be approximated further using (1+z)2 = 1+2z approximately, so that
1+2Annualized= 1+2r - s2
or
[b] Annualized= r - s2/2
>You're talking approximation here, yet you just said the solution to Ito was ...
Exact? Yes. If you believe that stock prices behave exactly as per [Ito*]
then you also believe that Annualized=r-s2/2.
On the other hand, I obtained (1+Annualized)2 = (1+Mean)2 - StandardDeviation2
by assuming only that the returns were small. There was no assumption concerning their distribution, just that a 5% return
(for example), written as r = 0.05, is "small". In any case, for "small" returns, [a] and [b] are equivalent.
>Can I ask a question?
Sure.
>Is 100 kilometres small ...
Of course not! What a silly ...
>... compared to the distance to the sun?
Uh ... sorry, you're quite right. I meant to say: for returns which are "small" compared to "1".
>You have an exact solution and yet you used the approximate Excel-1?
Good point. Let's use:
|
Excel-2: Pn = Po*EXP((r - s^2/2)*t + s*B)
where, to mimic a Brownian Motion, we use: B(t+dt) = B(t) + NORMINV(RAND(),0,1) with B(0) = 0. Typical solutions would look like Figure 6 and a solution and its Brownian companion are shown in Figure 7 where r - s2/2 = 0.05 - 0.102/2 = 0.045  Figure 7 |  Figure 6 |
|
For small volatility (meaning s, the Standard Deviation, is small), the Brownian Motion has less influence on the Price,
as indicated in Figure 8. Indeed, if s =0 we'd have one of those smoooth curves with constant growth at r = 0.05 or 5%. >So you believe all this stuff?
|  Figure 8 |
What bothers me a bit is the assumption that the next random stock price change is independent of the previous random change. That's part of the Brownian assumptions: the ΔBk are independent. The random changes in price are independent.
>But there's that smooth, non-random component, eh?
Yes, but haven't you noticed that, if your favourite stock goes up 5% today, you can almost guarantee that investors will sell tomorrow and the price will go down ... and that 5% ain't the smooth component.
>Profit taking?
Profit taking.
>So can you incorporate that into Ito-math?
Before we try that, let's use this Ito stuff to get the Black-Scholes formula for Option pricing.
>You can do that?
Me? Well, it can be done. Let's give it a try.
 to Continue
to Continue
