| Stutzer and Sharpe |
I never really liked the Sharpe Ratio
>Huh? Everybuddy likes the Sharpe Ratio!
Not me.
In particular, I don't like the use of the word "risk" to mean portolio volatility.
What's volatility got to do with risk?
If my monthly returns are 20% greater than yours, my volatility is the same as yours, but is my "risk" the same?
Is that a reasonable notion for the idea of "risk"?
I don't think that ...
>So what else would you use?
Well, for one thing, I'd like greater "risk" to imply a greater probability of losing money or having negative returns.
When I read that:
"The portfolio with the largest Sharpe Ratio has the highest return-to-risk ratio" it makes me ill. Return-to-Risk?
>Okay! So what else would you use?
I'll remind you that the Sharpe Ratio measures the expected (or Mean) excess return, over and above some benchmark or risk-free return
divided by the volatility (which is too often associated with "risk"!):
[1A] Sharpe Ratio = Mean[ Return - Risk-free] / SD[Return]
where SD is the Standard Deviation (or volatility) of portfolio returns.
Note that we could also consider:
[1B] Sharpe Ratio = Mean[ Return - Benchmark] / VAR1/2[Return - Benchmark]
where VAR is the Variance (or SD2) of portfolio returns.
If the benchmark is a constant, then VAR1/2[Return - Benchmark] = VAR1/2[Return] = SD[Return] and [1A] and [1B] are identical.
Okay, so we'll now look at returns compared to some benchmark or investor-selected target return.
We then look at the probability that these returns will not exceed this target ... that'd be bad, eh?
We then choose a portfolio which makes this probability decay to zero as our time horizon increases.
And what's the maximum possible decay rate?
That's the Stutzer Index.
>Huh?
| the Stutzer Index revealed |
Here we follow Stutzer (University of Colorado):
- If r is a return (weekly, monthly ... it doesn't matter), we consider the gain factor to be 1+r. Note that r = 0.123 refers to a 12.3% return.
- Consider a sequence of portfolio gain factors: p1, p2, p3 ... etc.
- The value of a $1.00 portfolio after n periods is
[2A] P(n) = p1 p2 ... pn. - If the $1.00 were invested in some "benchmark" portfolio with gain factors b1, b2 ... this portfolio would be worth
[2B] B(n) = b1 b2 ... bn. - To compare the two portfolios, we take the difference in their logarithms:
[2C] log(P(n)) - log(B(n)) = log(P(n) / B(n)) = Σ log(pk) - Σ log(bk) ... the sum going from k = 1 to k = n - The average difference is then given by:
[2D] S = (1/n) log(P(n) / B(n)) = (1/n) [Σ log(pk) - log(bk)] ... the sum going from k = 1 to k = n - Note that our portfolio will outperform the benchmark portfolio (over n periods) if P(n) > B(n), hence if S > 0.
- We assign to our portfolio a probability that S > 0. We call this Pr[S > 0].
Alas, the ranking of portfolios may vary, depending upon the time horizon, measured by n.
So we develop a ranking which holds for sufficiently long time periods ... meaning sufficiently large values for n.
Note that the probability that a portfolio will outperform the benchmark portfolio is Pr[S>0].
The probability that it will underperform is then Pr[S≤0].
Again, following Stutzer, we'll avoid portfolios for which Pr[S≤0] > 0, for large n.
>Huh?
If we underperform the benchmark, that's bad. Consider the average investor.
If her portfolio has a small chance of beating the benchmark
(meaning that Pr[S>0] is small), she'll just invest in the benchmark itself, right?
So (again following Stutzer) we rank portfolio strategies for which the limit of S, as n goes to infinity, is greater than 0.
That is:
 (1/n) log(P(n) / B(n))
= (1/n) [Σ log(pk) - log(bk)] > 0.
(1/n) log(P(n) / B(n))
= (1/n) [Σ log(pk) - log(bk)] > 0.
>Like investing in the S&P 500?
Yes.
- Consider the probability of underperformance, namely Pr[S≤0], and identify those portfolios for which this decays to zero as
n
 ∞.
∞.
- The faster that Pr[S≤0] 0 , the better the portfolio
... since then the probability of beating the benchmark, Pr{S>0], is greater.
- The underperformance rate of decay is then the Stutzer Index.
Our problem now is to explain the decay rate of the underperformance probability obtained by Stutzer :
[3] Dp = 
|
where E[ ] means Expected (or average) value.
So to get Dp, the rate of decay for our portfolio (compared to a benchmark portfolio), we do this:
- Pick some positive number γ and, at the n-period time, evaluate the ratio R(n) = P(n) / B(n).
- Determine the logarithm of the Expected value of R(n)-γ.
- Divide this log by -n and let n ∞.
- Then repeat steps 1 - 3 to find that value of γ which maximizes the number obtained in step 3.
>zzzZZZ
Look carefully:
- R(n) = P(n) / B(n) is the ratio of portfolios after n periods.
- According to our definition of S in 2D, above, this ratio can also be written like so: R(n) = P / B = enS
- We can then rewrite the decay, Dp, in terms of the maximum of the limit of the Expected value of: e-γnS
- Suppose that γ is
the γ-value that maximizes the limit as n ∞.
Then we'd have, for large n-values, Dp ≈ (-1/n) log E[e-γnS]. - This can also be written like so: -e-n Dp ≈ -E[e-γnS] = E[-R-γ]
- We note that, for large n, the left side of this equation increases as Dp increases, so large decay rates mean larger probability of underperformance of our portfolio (compared to the benchmark portfolio).
>This is all greek to me! Where on earth did that expression [3] for Dp come from?
Uh ... that's the solution to the problem of finding Pr[S≤0] and it's called the Gärtner-Ellis Large Deviations Theorem.
This theorem gives the decay rate of the undeperformance probability.
>You're kidding, right?
We'll get to Gärtner-Ellis later ... maybe.
>Warn me when you do.
Notice that we're using Gärtner-Ellis in connection with a ratio of portfolios: ours and some
benchmark which may be the S&P 500 or, if we're a fund manager, it could be the average portfolio of other fund managers
(which we wish to better).
Notice, too, that our objective is to look at the probability that our portfolio will underperform, compared to the benchmark, then make this probability decay to zero as time increases (so, hopefully, we're unlikely to underperform), then maximize the rate of decay of this probability.
The faster the decay, the better our portfolio strategy ... so we want that portfolio strategy which provides the maximum decay rate.
>zzzZZZ
| Logarithmic and other Utilities |
Remember when we talked about utility functions?
Investors don't attempt to maximize their expected gain but rather their utility and each investor has a personal utility function and ...
>Huh?
There's that Bernoulli example:
You toss a coin umpteen times.
When a heads comes up you stop.
If a head comes up in m tosses, you win $2m.
Your expected gain is infinite, but would you pay a jillion dollars to play this game?
No, but you might pay, say $25.
If we take not the gain of 2m but rather a "logarithmic utility", 20 log(2m) ,
then the expected value of this utility function is $27.73.
|
>Why 20 log(2m)? Why not 47 log(2m)?
You pick your own utility function. It's a personal thing. For investments, it'd depend upon your aversion to risk. Figure 1A shows some possible utility functions. Notice that they are increasing functions, so if the utility is larger, you're a happy camper.
For our particular problem, an exponential utility function seems to be the way to go.
>That's the reason for maximizing over γ, right?
You'll notice that we rearranged things, above, like so:
>And up pops an exponential utility, right?
>And this all makes sense to you?
| 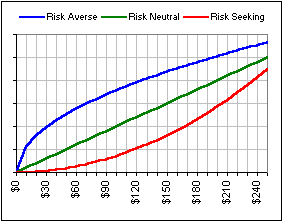 Figure 1A
|

Some observations:
- If we want our portfolio, P, to do better than a benchmark portfolio, B, we could use
the logarithmic utility and simply maximize:
- E[e-γ(P - B)] - Stutzer, on the other hand, uses a power utility function -R-γ over long time periods:
- (1/n) log E[e-γ(log(P/B))] = - (1/n) log E[R-γ] - Note: the logarithm of the ratio of portfolios after n periods is log(P) - log(B) = log[ P / B ].
- If the annualized returns are pn and bn respectively, then, $1.00 portfolios would grow to:
P(n) = (1+ pn)n and B(n) = (1+ bn)n - The log of the ratio is then:
log[ P(n) /B(n) ] = n log[(1+ pn) /(1+ bn)] - The Stutzer Index is then the maximum of:
- (1/n) log E[e-γ n log[(1+ pn) /(1+ bn)]] - This can be written as: - (1/n) log E[ [(1+ pn) /(1+ bn)] -γ n ]
>Does that make things easier?
Maybe.
|
Suppose we ignore that Expected value and just look at the behaviour of
- (1/n) log[ [(1+ pn) /(1+ bn)] -γ n] = γ log[ (1+ pn) / (1+ bn)] as n gets larger. Figure 2 shows such a graph, where the portfolio returns are randomly selected from a normal distribution with
mean return = 10% and volatility = 30% and
>And γ?
|  Figure 2 |
More observations:
|  Figure 3 |
>Will there be a spreadsheet?
Uh ... maybe.
Here's what we'll do:
- We download prices for three stocks (or mutual funds) and calculate the weekly returns for each.
- We pick some allocation, like 70% Asset A, 20% Asset B and 10% Asset C and calculate the weekly returns for this portfolio.
- We also download the weekly prices (and calculate the returns) for our benchmark: the S&P 500.
- We calculate the ratio of total returns over n weeks, namely R(n), for n = 1, 2, 3 ... 200.
- We pick some value for gamma (that's γ) and calculate (for each n) -R-γ.
- We calculate the average of -R-γ over 200 weeks: call it AVG. (It's our Expected value and it'll be a negative number.)
- We calculate D = -(1/200)log[-AVG].
- We vary gamma (that's γ) in order to get the largest value of D. (Expressed as a percentage, that's our Stutzer Index for this portolio.)
>N = 200? Is that infinite?
Well, we really want the limit as n ![]() infinity, so we'll plot the D-value versus n to see where it's going.
infinity, so we'll plot the D-value versus n to see where it's going.
We get this:
 |
>You picked gamma = 75?
Well, I actually tried all values from 0 to 200 in steps of 5 and that gave me the biggest D-value.
>And that 70% + 20% + 10% is the best allocation?
Well, no. I also calculate a bunch of allocations and find the "best" (in the sense of the largest D-value) is like so:
 |
>Hmmm ... sounds like a lot of work, to find the "best".
Not really.
There are buttons ... 

>And when you vary gamma, you're sure you got yourself a maximum?
There's a picture ... 

>So how do I get the spreadsheet?
Click here and if that don't hardly work, try a RIGHT-click and Save Link or Save Target.
Note: There are no guarantees about this spreadsheet. It may (or may not!) work proper ... but it's great fun

 for Part II
for Part II